Генерируй на компо правильно!

Как наверное уже многие заметили, на двух (как минимум) предстоящих демопати, проходящих в России в конкурсах графики появились новые пункты — это генерируемая с помощью AI (не путать с алгоритмической) графика.
Например, на [DiHalt 2024 Summer] появились вот такие конкурсы:
- AI LowEnd Graphics (Графика для ретро-платформ, сопоставимых с ZX-Spectrum/C64/AmstradCPC/БК/etc, сгенерированная с помощью AI)
- AI Wild (Любые работы, сгенерированные AI, или с использованием AI)
На [Chaos Constructions 2024] тоже появились конкурсы связанные с AI:
- AI Music (любая музыка, при создании которой применялся ИИ (в том числе искусственные нейронные сети, GAN и подобные технологии)
- AI Graphics (любые изображения, при создании которых применялся ИИ (в том числе искусственные нейронные сети, GAN и подобные технологии)
И если на Chaos Constructions организаторы и составители правил конкурсов не акцентируют создание AI графики для ретро платформ, то в случае с DiHalt совсем наоборот, приветствуется AI графика именно под ретро компьютеры. Под любые другие (современные платформы) работы скорее всего тоже примут, но у же в AI Wild, по видимому.
Отсюда возникает вопрос: а что можно вот так взять и нагенерировать графики под спектрум?
Да, можно, взять и нагенерировать. Но, как всегда, есть небольшие нюансы и с ними мы сейчас попробуем разобраться.
Во-первых, никакая GAN-подобная нейросеть не выдаст вам в качестве результата .scr, который вы сможете загрузить в свой zx spectrum или спектрум совместимый компьютер.
Во-вторых, ни одна модель не выдаст вам pixel perfect изображение с которым не надо будет производить дополнительных манипуляций внешними скриптами\программами.
В-третьих, идеального решения не существует, и возможно множество вариантов получения нужного изображения в зависимости от конкретных задач.
Я расскажу о том способе, который мне кажется наиболее доступным и гибким.
В качестве нейросети будем использовать Stable Diffusion.
Есть несколько сборок, позволяющих у себя локально на компьютере развернуть SD — NMKD, AUTOMATIC1111, а также несколько портативных сборок на основе того же AUTOMATIC1111 и прочих.
Я пробовал развертывать и NMKD и AUTOMATIC111 и они прекрасно работают, но в конце концов я остановился на сборке FOOOCUS — это переосмысление и пользовательского интерфейса и пользовательского опыта, можно сказать, что это приближение Stable Diffusion к Midjourney как по качеству генераций, так и по простоте использования. Сборка FOOOCUS также основана на Stable Diffusion XL, т.е. стандартное разрешение и качество генераций выше стандартного Stable Diffusion.
Казалось бы, зачем нам сверхвысокое разрешение и качество, если наша задача генерировать пиксельарт для ретрокомпьютеров? Но, дело в том, что чем качественне базовая генерация, тем качественнее будет и наш пиксилезированный результат.
Итак, наша главная ссылка — [https://github.com/lllyasviel/Fooocus]. Это репозиторий где качаем архив, распаковываем и запускаем run.bat (это что касается windows). Также FOOOCUS запускается на Linux машинах и на MacOS, на главной репозитория всё расписано как это сделать, но подтвердить или опровергнуть работоспособность я не могу. К тому же, на разных платформах разные требования к железу (видеокарта\память).

Точно могу сказать, что на Windows у меня прекрасно работает в минимальной конфигурации на NvidiaGTX 1060\6GB. И, конечно, гораздо резвее на NvidiaRTX4060\8GB.
При запуске и установке необходимых библиотек и моделей в браузере открывается веб-интерфейс, весьма аскетичный и минималистичный.

Пишем в поле свой запрос, жмём Generate и ждём когда электронные нейроны нам соберут нашу картинку.
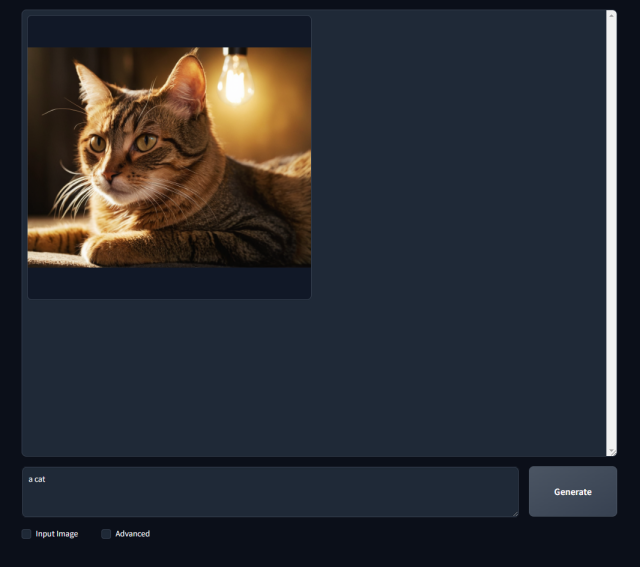
Ого! У нас получилось! Отличный нейрокот!
Хорошо, установили FOOOCUS, поигрались, погенерировали картинок, удивились и что дальше, как нам получить вожделенные пиксели?
А очень даже просто, ведь мы используем FOOOCUS, а не стандартную сборку AUTOMATIC1111 (хотя и там всё то же самое делается, только сложнее и с тоннами разнообразных тонких настроек). Самое удивительное и классное в данной сборке — это встроенные стили, которые добавляют все уточнения в запрос автоматически, и тут они скрыты от пользователя. Ставим галочку [Advanced] и справа откроется дополнительное меню: выбранная настройка, скорость генерации, размер изображения, формат и количество выходных картинок, негативный промт.

Следующая вкладка открывает настройки стиля.

Как видно, по умолчанию (в зависимости от начальной настройки) выбираются несколько стилей. Их можно включать в разных комбинациях и в любом количестве. По опыту могу сказать, что больше 3-4 стилей включать не стоит т.к. генерация превращается в нечно невообразимое и теряет контекст запроса. Чтож, даже на этапе стилизации мы вполне можем генерировать некое подобие пиксельарта. При наведении курсора на стиль нам показывается небольшое окно, где можно увидеть к чему приводит конкретная стилизация.

Давайте посмотрим что нам даст простой выбор стиля «SAI Pixel Art».

Котик скорее стал собранным из лего, но в каком-то смысле пиксельным. Хорошо бы сделать его еще и плоским. В этом весьма неплохо помогает выбор «Cel Shaded Art» стиля.

Вот! Это уже близко к тому, что мы хотим получить в конечном итоге. Уже на этом этапе вполне возможно попытаться сконвертировать полученное изображение любым вашим конвертором. Где найти конвертер или хотя бы ссылку на то, где его найти вы конечно же знаете — на [zxboot]!
Но мы пойдём чуть дальше и чуть глубже, нам уже на этапе генерации нужно получить наиболее близкое к спектруму изображение, чтобы максимально исключить потери графической информации при конвертировании. И желательно уменьшить влияние клешинга на конечное изображение. Для этого нам нужно дополнительно установить один чекпоинт модели и одну лору.
Чекпоинт — это базовая модель, а лора — это модель обучения, которая позволяет обучать не общий случай получения генерации, а определенную стилистику или концепцию. Например, определенную одежду на всех возможных генерациях людей, определенный тип лица или определенные позы, также лора может быть предобучена на генерацию определенных предметов.
Еще одна ссылка — [https://civitai.com/]. Это большое коммьюнити по распространению пользовательских моделей, генераций, статей и прочего, связанного с генерацией изображений. Брать модели и лоры мы будем именно здесь.

Отсюда нам нужно скачать модель [DreamshaperXL] — 6,46GB
И LORA [zxspectrum-style] — 162MB
Модель помещаем в каталог Fooocus/models/checkpoints/
Лору в Fooocus/models/loras/
Перезапускаем FOOOCUS.
В интерфейсе FOOOCUS во вкладке Model выбираем нашу скачанную модель, ниже в поле LoRA 1 выбираем нашу лору zxspectrum-style, вес нужно больше единицы, я ставлю 1,3-1,5. Пробуем сгенерировать нашего котика снова. Модель будет заново грузиться в память графической карты, поэтому первичная генерация займёт времени побольше, чем последующие, так что не пугайтесь.

Ну смотрите, наш котик весьма преобразился! Можно сказать даже немного оспектрумился. Если поиграть немного с настройками весов лоры и стилей, а также переключиться на Quality вместо Speed, то можно получить еще более интересные варианты.

Можно ли не качать дополнительную базовую модель и ограничиться той, что скачалась при установке FOOOCUS?
Да, можно генерировать на той, что есть, но автор лоры рекомендует именно DreamshaperXL, так что прислушаемся к совету. И еще, для многих лора есть триггерные слова, которые накидывают стиль с лоры на базовую модель, так вот наши триггеры это — «zxspectrum style», добавим их в наш запрос.

Ну вот, мы максимально спектрумизировали нашего котика. Настало время еще больше приблизить его к спектруму с помощью нехитрого способа — конвертирования.
Тут уж кто на что горазд и может использовать любой удобный конвертер. Лично я давно и с большим удовольствием пользуюсь Image Spectrumizer (img2spec) от Jari Komppa. Вот ссылка на [гитхаб], и [прямая ссылка на скачивание] и ссылка на [сайт], там еще есть много интересного, например, вполне вменяемое [руководство по программированию на ассемблере для z80].
Немного поигравшись теперь уже с настройками конвертера, получим нашего на 100% оспектрумированного котика.

И всё это без единого исправленного или поставленного руками пикселя, чего мы и добивались. Как видно из предпросмотра конвертера, картинка практически не меняется, клешинг местами виден, но не критично, потерялись усы, но я уверен, если чуть подольше покрутить ползунки, то вернуть можно утраченные детали и еще немного облагородить картинку. Более того, на этом этапе можно даже с цветами поиграться немного…


Выгружаем полученный результат в .scr, задача выполнена, можно отсылать AI-котика на конкурс AI low-end graphics.
Кстати, если хотите увидеть полные настройки вашего запроса, по которому генерируется конечное изображение, его можно найти в папке outputs/log.html
Full RAW prompt:
Positive: Cel Shaded Art, zxspectrum style cat, 2D, flat color, toon shading, cel shaded style, pixel-art zxspectrum style cat. low-res, blocky, pixel art style, 8-bit graphics
Negative: ugly, deformed, noisy, blurry, low contrast, sloppy, messy, blurry, noisy, highly detailed, ultra textured, photo, realistic
Там же можно посмотреть и остальные параметры генерации.

На этом у меня всё. Успешных генераций!
1 комментарий