Ускоряем DeSmuME

Какое-то время назад зоопарк форматов, поддерживаемых ZXTune пополнился еще одним экспонатом — .2sf. Типичный представитель семейства Portable Sound Format (.psf, .psf2, .ssf, .dsf, .usf, .gsf, .snsf, .2sf, .qsf), предназначенный для хранения дампов памяти с музыкой игр для карманной приставки Nintendo DS.
Для воспроизведения используется библиотека vio2sf от Christopher Snowhill на основе эмулятора DeSmuME. На далеко не самом быстром референсном устройстве и случайно выбранных треках библиотека показывала достаточное быстродействие, поэтому она была портирована as is, без оптимизаций (хотя беглый взгляд на код и вызывал зуд в руках). К тому же, будучи измученным
У реальности же был несколько другой взгляд на положение вещей. Все началось с репорта пользователя о том, что после очередного релиза android-версия плеера начала заикаться на воспроизведении некоторых .2sf треков. Короче говоря, было принято решение таки заняться оптимизацией.
Шаг 0. Подготовка
В силу специфики подавляющего большинства Android устройств, оптимизация должна ускорить работу на ARM. В качестве тестового полигона выступает маленькая, но гордая Raspberry Pi первой реинкарнации — давно уже использую ее для таких целей, а также домашнего веб-сервера и vpn-гейта. На безрыбье пойдет и qemu, но практика показала, что реальное железо таки лучше.
Прежде чем ускорять что-то, нужно измерить
$ ./zxtune123 --benchmark 1 ../../01\ Spinning\ the\ Tale.mini2sf
x0.70 (2SF) ../../01 Spinning the Tale.mini2sf
OMG! Raspberry Pi (1x700MHz ARM) недостаточно для воспроизведения этого трека! Пусть целью всех этих телодвижений будет исправление этой несправедливости:)
Смотрим отчет профилировщика:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls s/call s/call name
25.79 19.76 19.76 51359049 0.00 0.00 armcpu_exec
20.88 35.76 16.00 57925896 0.00 0.00 MMU_read32
14.75 47.06 11.30 488028 0.00 0.00 SPU_MixAudio(NDS_state*, bool, SPU_struct*, int) [clone .constprop.14]
5.87 51.56 4.50 488028 0.00 0.00 NDS_exec_hframe
2.47 53.45 1.89 18510255 0.00 0.00 TWOSF_resampler_set_rate
2.47 55.34 1.89 4639311 0.00 0.00 MMU_write32
1.98 56.86 1.52 18510255 0.00 0.00 TWOSF_resampler_get_sample
1.93 58.34 1.48 320607 0.00 0.00 resampler_fill
1.92 59.81 1.47 17693319 0.00 0.00 TWOSF_resampler_write_sample
1.57 61.01 1.20 3898120 0.00 0.00 OP_LDR_P_IMM_OFF
1.42 62.10 1.09 18510255 0.00 0.00 TWOSF_resampler_remove_sample
1.20 63.02 0.92 36203574 0.00 0.00 TWOSF_resampler_get_free_count
1.20 63.94 0.92 662974 0.00 0.00 OP_STMDB_W
0.99 64.70 0.76 2126738 0.00 0.00 OP_LDRB_P_IMM_OFF
0.98 65.45 0.75 4583923 0.00 0.00 OP_CMP_IMM_VAL
0.95 66.18 0.73 2527439 0.00 0.00 MMU_read8
По отчету видно, что в лидерах потребления CPU у нас находится эмуляция ARM, доступ к памяти и рендеринг звука в SPU (Sound Processing Unit).
Шаг 1. Очистка
Первые набеги на с шашкой наголо недвусмысленно дали понять, что сначала следует прибраться — вырезать всякий закомментированный и/или неиспользуемый код. Так уж сложилось, что его (такого кода) достаточно много. Ведь эмуляция звуковой части приставки на основе дампа памяти всяко проще, нежели полноценный эмулятор всей приставки. Итак, план действий:
— удаляем немного закомментированного кода в SPU
— удаляем неиспользуемый код SPU и упрощаем оставшийся
— вырезаем все ненужное, за что цепляется глаз: поддержку gdb, профилирование MMU, экспериментальную поддержку WiFi, еще один закомментированный код и поддержку coverage
Benchmark с благодарностью отвечает на удаление поддержки coverage, ибо проверки не бесплатны:
$ ./zxtune123 --benchmark 1 ../../01\ Spinning\ the\ Tale.mini2sf
x0.71 (2SF) ../../01 Spinning the Tale.mini2sf
Шаг 2. Небольшое причесывание структур
По прошлому опыту оптимизаций могу сказать, что сгенерированный код под ARM очень и очень чувствителен к расположению элементов в структурах. Это следствие ограничений архитектуры ARM на работу с константами. Как написано в одном руководстве:
You cannot load an arbitrary 32-bit immediate constant into a register in a singlewww.idt.mdh.se/kurser/cdt214/ARM_Assembler_Guide.pdf
instruction without performing a data load from memory. This is because ARM
instructions are only 32 bits long.
…
In ARM state, you can use the MOV and MVN instructions to load a range of 8-bit constant
values directly into a register:
— MOV can load any 8-bit constant value, giving a range of 0x0 to 0xFF (0-255).
It can also rotate these values by any even number.
— MVN can load the bitwise complement of these values. The numerical values are -(n+1)
В переводе на русский: в коде инструкции отводится только 8 бит на аргумент. Если можно получить искомую константу путем сдвига другой 8-битовой константы на четное число бит влево или вправо, то все ок, загрузка уместится в одну операцию. В thumb режиме все еще жестче — даже сдвиги недоступны, только хардкор, только 0-255!
В противном случае используется другой, более сложный (и медленный!) способ:
; load register n with one word
; from the address [pc + offset]
LDR rn [pc, #offset to literal pool]
Literal pool обычно представляет собой набор констант в конце (а то и прямо в середине) функции.
Оптимизация обычно сводится к двум действиям:
— сокращение размеров структур
— перенесение частоиспользуемых элементов структур в начало
После навсидку выполненных оптимизаций в коде firmware, поддержке fifo и MMU померяем профит:
$ ./zxtune123 --benchmark 1 ../../01\ Spinning\ the\ Tale.mini2sf
x0.80 (2SF) ../../01 Spinning the Tale.mini2sf
Оп-па! Ничего особого не делая, получаем 13% (0.8/0.71=1.13) прирост скорости абсолютно нахаляву.
Ради интереса, можно посмотреть как изменился код доступа к памяти:
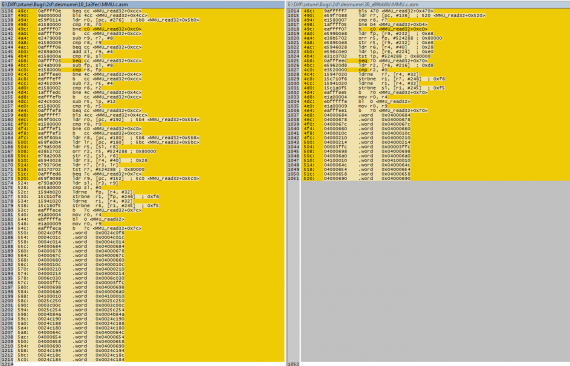
Функция стала короче на 160 байт, а число «неудобных» констант уменьшилось почти в 2 раза с 29 до 15.
Шаг 3. Оптимизируем SPU
Краткий экскурс в матчасть дает общее представление о железном оригинале устройства и его возможностях:
— 16 каналов
— поддержка 4- (ADPCM), 8- и 16-битных семплов
— поддержка генерации прямоугольных импульсов с переменной скважностью и псевдослучайного шума
Путем несложных манипуляций, находятся три трека, поддерживающих вместе все возможные способы генерации звука. Они будут использоваться в качестве базы для регрессионных тестов дабы проконтролировать, что изменения и оптимизации ничего не сломали. Алгоритм простой — рендерим эти треки в .wav файлы и считаем по каждому md5 сумму. Нет изменений — ничего не сломано, profit.
Избавление от double
Некий бардак в исходниках на тему float/double привлек внимание и вызвал желание навести порядок. Ну что ж, пусть останется
Тут же стреляет регрессионный тест. Анализ отрендеренных .wav файлов позволяет все списать на тонкости округления.
Benchmark не показывает практически никакого прироста. Ну и ладно, не у всех есть hardware float, пусть этот фикс будет для них.
Упрощение циклов
Функция рендеринга излишне запутана, на каждый семпл(!) зовется функция установки параметров ресемплера и вычитываются параметры формата и микширования.
Было (с купюрами):
void ____SPU_ChanUpdate(NDS_state *state, int CHANNELS, int FORMAT, SPUInterpolationMode INTERPOLATE_MODE, SPU_struct* const SPU, channel_struct* const chan)
{
for (; SPU->bufpos < SPU->buflength; SPU->bufpos++)
{
s32 data;
switch(FORMAT)
{
case 0: Fetch8BitData(INTERPOLATE_MODE, state, SPU, chan, &data); break;
case 1: Fetch16BitData(INTERPOLATE_MODE, state, SPU, chan, &data); break;
case 2: FetchADPCMData(INTERPOLATE_MODE, state, SPU, chan, &data); break;
case 3: FetchPSGData(INTERPOLATE_MODE, chan, &data); break;
}
SPU_Mix(CHANNELS, SPU, chan, data);
}
}
void FetchXXXData(SPUInterpolationMode INTERPOLATE_MODE, channel_struct *chan, s32 *data)
{
resampler_set_rate( chan->resampler, chan->sampinc );
....
}
void SPU_Mix(int CHANNELS, SPU_struct* SPU, channel_struct *chan, s32 data)
{
switch(CHANNELS)
{
case 0: MixL(SPU, chan, data); break;
case 1: MixLR(SPU, chan, data); break;
case 2: MixR(SPU, chan, data); break;
}
}
Выносим все вычитывания параметров за скобки цикла и пользуемся шаблонными функциями С++.
Стало (с купюрами):
void _SPU_ChanUpdate(SPU_struct* const SPU, channel_struct* const chan)
{
if (chan->pan == 0)
__SPU_ChanUpdate<MixL>(SPU, chan);
else if (chan->pan == 127)
__SPU_ChanUpdate<MixR>(SPU, chan);
else
__SPU_ChanUpdate<MixLR>(SPU, chan);
}
template<MixFunc Mix>
void __SPU_ChanUpdate(SPU_struct* const SPU, channel_struct* const chan)
{
switch(chan->format)
{
case 0: Render8BitSample<Mix>(SPU, chan); break;
case 1: Render16BitSample<Mix>(SPU, chan); break;
case 2: RenderADPCMSample<Mix>(SPU, chan); break;
case 3: RenderPSGSample<Mix>(SPU, chan); break;
}
}
template<MixFunc Mix>
void RenderXXXSample(SPU_struct* const SPU, channel_struct *chan)
{
resampler_set_rate( chan->resampler, chan->sampinc );
for (; SPU->bufpos < SPU->buflength; SPU->bufpos++)
{
...
Mix(SPU, chan, data);
}
}
Результат:
$ ./zxtune123 --benchmark 1 ../../01\ Spinning\ the\ Tale.mini2sf
x0.83 (2SF) ../../01 Spinning the Tale.mini2sf
Избавление от floating point
Судя по всему, float позиция в семпле- пережиток тех времен, когда рендеринг осуществлялся на звуковой частоте. С тех пор был добавлен ресемплер. Удаляем пережитки и смотрим результат:
$ ./zxtune123 --benchmark 1 ../../01\ Spinning\ the\ Tale.mini2sf
x0.89 (2SF) ../../01 Spinning the Tale.mini2sf
Неплохо!
Пререндеринг ADPCM семплов
После оставшихся за кадром изменений по улучшению структуры кода, фикса найденных проблем (да здравствуют регрессионные тесты!) остается последний штрих.
Код рендеринга содержит много фукнций, но компилятор бодро сливает их в одну. Ее-то и видно в профиляторе. Временно запрещаем ему эту самодеятельность и смотрим на результат. Ба! В топ теперь выходит декодирование ADPCM семпла! Решение простое, как валенок — предварительно отрендерить семпл целиком, избавившись от логики доступа к полубайтам и необходимости сохранять контекст декодера для обеспечения циклов семпла.
Результат:
$ ./zxtune123 --benchmark 1 ../../01\ Spinning\ the\ Tale.mini2sf
x0.94 (2SF) ../../01 Spinning the Tale.mini2sf
Промежуточные итоги
Скорость работы увеличена на 34% (0.94/0.70=1.34) Цель еще не достигнута, но свет в конце туннеля уже забрезжил:)
To be continued?
- Да
- Нет, хватит
5 комментариев