Сжатие данных для современного кодинга под Z80

Многие программы сделанные на спектруме в 1980е не использовали технологии упаковки данных. Вообще, сжатие было не так широко известно, упаковщиков было мало. RLE не считалось позорным алгоритмом сжатия! Сейчас ситуация изменилась; почти каждый современный релиз, как минимум, придёт в упакованном виде, а как максимум — будет хранить часть данных запакованными и распаковывать их на лету, по мере надобности. Тем не менее, разговоры о компрессорах часто показывают, что редкий кодер видит общую картину вещей. Люди используют один и тот же пакер десятилетиями; иногда неплохой, просто устаревший пакер, иногда — пакер, который даже 10 лет назад не стоило начинать использовать. Я сделал серию тестов для десяти достаточно модных упаковщиков, чтобы попробовать понять, какой пакер нужно брать для современного приложения. Надеюсь, вам будет тоже интересно (и полезно) посмотреть на то, как выглядят результаты.
Вводная часть
Вообще, хочу начать с того, что самое активное применение пакеров в 1990-е — переупаковка кассетных и дисковых релизов — меня не очень интересует. Я смотрю на пакеры в прицеле применения их для упаковки данных в моих программах (чаще всего — демах). Когда я говорю о распаковке данных, я скорее всего думаю о распаковке на лету, прямо во время работы программы, а не один раз, сразу после загрузки. Очень многие пакеры несут на себе отпечатки старых привычек: присоединяют распаковщики к данным, пытаются предусмотреть релокацию декомпрессоров и кодовых блоков по окончанию загрузки и т.п. В этой статье я буду игнорировать фичи этого рода. Меня интересует только упаковка данных, по возможности, без ненужных заголовков и идентификаторов, и распаковка не сложнее чего-то вроде:ld hl,PackedData : ld de,DestinationAddress : call DecompressДля проведения тестов я приготовил новый набор данных, чтобы лучше понимать сильные и слабые стороны каждого пакера. Т.к. меня интересует упаковка для Z80, я сознательно исключил файлы больше 64Кб. Все приготовленные файлы разбиты на 5 групп. Первые две группы — «calgary» (8 файлов) и «canterbury» (5 файлов) включают все файлы размером меньше 64К из стандартных корпусов сжатия (полные корпусы можно найти здесь). Группа «graphics» содержит 30 картинок для спектрума, в основном современных, разной степени сложности (сжимаемости), и разных типов, включая различные мультигигаколоры и бордеры. Группа «music» содержит 24 музыкальных файла, для разных музыкальных редакторов, включая несколько биперных треков. Наконец, группа «mixedzx» содержит 10 файлов со смешанными данными (7 неупакованных игр, одно неупакованное демо и два частично упакованных демо). Мне хотелось предоставить упаковщикам разнообразные типичные «живые» данные, с различной степенью сжимаемости, и посмотреть, как пакеры справятся с этой задачей.
Есть ещё один момент, который, мне кажется, не все понимают. Упаковка данных — это специальный вид перекодирования, и, для большинства пакеров, это перекодирование может осуществляться по-разному. Грубо говоря, один и тот же пакер может упаковать одни и те же данные лучше или хуже. У многих алгоритмов сжатия попроще можно реализовать оптимальный пакер, т.е. такой пакер, который всегда выдаст минимальный размер упакованных данных для своего формата. Оптимальность редко достижима в современных архиваторах, из-за высокой сложности применённых алгоритмов и очень низкой скорости оптимального сжатия, особенно для больших файлов. Оптимальность почти всегда достижима в упаковщиках для 8-битных машин, т.к. у нас сравнительно маленькие файлы и сравнительно примитивные алгоритмы сжатия. Разница между оптимальным и неоптимальным сжатием может быть довольно существенной. Например, оптимальный упаковщик для формата MegaLZ был написан намного раньше оптимального упаковщика для формата Hrust 1, поэтому на форумах можно найти результаты старых тестов, в которых MegaLZ сжимает в среднем лучше. В этом тесте я постарался уточнить, какого рода пакер используется, и обязательно упоминаю это по тексту, чтобы понимать, какие различия связаны с форматом сжатия и какие — с недостатками существующих упаковщиков.
Информация о включённых в обзор компрессорах
Скажу сразу, что я не претендую что детально знаю каждый из этих упаковщиков. С некоторыми из них я работаю уже несколько лет, некоторые я потыкал исключительно сейчас, чтобы приготовить обзор. Информация не всегда полная; я могу в чём-то и ошибиться. Поэтому, я буду рад, если кто-то может дополнить имеющуюся у меня информацию или поправить какие-то неточности в описаниях.ApLib — универсальная библиотека упаковки данных для слабых машин, написанная Jørgen Ibsen, вот её официальная страница. Библиотека старая, была написана во вторую половину 1990-х. По алгоритмам — вариация LZSS с большим количеством дополнительных трюков (например, содержит коды для повторного использования недавно встреченных смещений, как в LZX. Такая зависимость кодов от контекста очень сильно усложняет оптимальную упаковку). Стандартный упаковщик appack.exe, который идёт в комплекте с библиотекой, добавляет к упакованным данным заголовок, поэтому им никто не пользуется. Вместо этого пользуются одной из сборок упаковщика, которая не пишет заголовков, например appack_raw.exe с сеговского форума SpritesMind, собранный нашим соотечественником r57shell. Стандартный упаковщик неоптимальный (жмёт чуть-чуть хуже оптимального упаковщика Hrust 1), но на наше счастье r57shell написал новый, более близкий к оптимальному (хотя всё ещё неоптимальный) упаковщик, который я переименовал для удобства в appack_r57shell.exe. Он уже существенно обгоняет Hrust 1 по сжатию. Самая последняя версия упаковщика находится здесь. Упаковка делается так:
appack_raw.exe c inputfile [outputfile.aplib]appack_r57shell.exe inputfile [outputfile.aplib]Первые, очень тормозные распаковщики на Z80 были написаны Dan Weiss для калькулятора TI83 и Maxim для Sega Master System; по-настоящему хорошие распаковщики были написаны уже для спектрума Metalbrain, Utopian и Antonio Villena, см. тред где их опубликовали. Я включил в этот тест 4 распаковщика.
- aplib156b.asm — компактный распаковщик, всего 156 байт, использующий регистры AF, BC, DE, HL, IX и, внимание, IY. В среднем он распаковывает один байт за 165 тактов Z80.
- aplib197b.asm — распаковщик побыстрее, занимает 197+2 байта и использует регистры AF, AF', BC, DE, HL, IX и, внимание, IY. Oн распаковывает один байт за 106 тактов Z80. Внимание! Этот и два следующих распаковщика, использующие AF', содержат неприятный баг, который заключается в том, что одна из команд SBC HL,BC подразумевает заранее сброшенный флаг C, из-за чего перед вызовом распаковщика требуется добавить пару команд:
or a : ex af,af' - aplib227b.asm занимает 227+2 байтa, использует регистры AF, AF', BC, DE, HL, IX и, внимание, IY, и распаковывает один байт за 102 такта Z80.
- aplib247b.asm занимает 247+2 байтa, использует регистры AF, AF', BC, DE, HL, IX и, внимание, IY, и распаковывает один байт за 100 тактов.
Exomizer — современный упаковщик, написанный Magnus Lind. Никакой документации по формату упаковки нет, но упаковщик доступен в исходных кодах. Я не разбирался в устройстве упаковщика и формате данных и не могу сказать, оптимален ли пакер (если кто-то знает — будет полезно узнать). Файл можно упаковать командой:
exomizer.exe raw inputfile -o [outputfile.exo]exomizer.exe raw -c inputfile -o [outputfile.exo_simple]Распаковщики Exomizer были написаны той же командой, что оптимизировала распаковщики ApLib.
- deexo.asm — основной, слегка неторопливый распаковщик. Занимает 169 байт, плюс, требует для своей работы буфер памяти в 156 байтов. Распаковщик использует AF, BC, DE, HL, IX и, внимание, IY. Скорость распаковки — 287 тактов на распакованный байт.
- Стандартный распаковщик содержит инструкцию, как существенно ускорить распаковку, добавив к распаковщику всего 5 байт; deexo_plus.asm — реализует эти рекомендации. Распаковщик занимает 174 байта; скорость распаковки — 248 тактов на байт.
Hrum — первый из трёх пакеров Дмитрия Пьянкова, попавший в этот обзор. Hrum позиционировался как пакер с неплохим сжатием и быстрой декомпрессией. По устройству он представляет из себя LZSS пакер средней сложности. Старые упаковщики Hrum для спектрума не были оптимальными, но mhmt.exe от lvd включает в себя оптимальный компрессор в формат данных Hrum, который вызывается следующим образом:
mhmt.exe -hrm inputfile [outputfile.hrum]Стандартная версия Hrum на спектруме прикладывала распаковщик к зажатому блоку, причём распаковщик был задуман так, чтобы автоматически разложить данные по памяти и запустить код (т.е. пакер задумывался для единовременной распаковки загруженных с ленты или диска данных). Для этого обзора я дизассемблировал стандартный распаковщик Hrum и адаптировал его для работы с блоками сжатых данных:
- unhrum_std.asm — занимает 104 байта, может также быть собран как релоцируемый распаковщик длиной 105 байт. Распаковщик использует AF, BC, DE, HL, BC', DE' и, внимание, HL'; релоцируемая версия использует IX. Скорость распаковки — 97 тактов на байт.
Hrust 1 — самый эффективный упаковщик Дмитрия Пьянкова. По внутреннему устройству Hrust 1 — это навороченный LZSS пакер с кучей дополнительных фишек, типа копирования блоков с дырками и динамически изменяемыми кодами ссылок (как в LZB). Как и Hrum, Hrust 1 позиционировался как пакер для единовременного разжатия загруженных данных, со встроенным распаковщиком, релокацией и т.п. фичами. Тем не менее, когда lvd реализовал упаковщик Hrust 1 в своём mhmt, он убрал из упакованных данных заголовки и прочие вспомогательные данные, а также приготовил соответствующие распаковщики. Таким образом, Hrust 1 сейчас можно использовать как библиотеку сжатия данных общего назначения. Упаковщик Hrust 1 в утилите mhmt неоптимальный; к счастью, Евгений Ларченко недавно написал новый оптимальный пакер для формата Hrust 1, который называется oh1c.exe. Этот пакер добавляет к сжатым данным стандартные заголовки Hrust 1; я взял на себя смелость слегка доработать упаковщик, чтобы он мог выдавать также и голые упакованные данные. Вызывается этот упаковщик следующим образом:
oh1c.exe -r inputfile [outputfile.hrust1]К mhmt было приложено 2 распаковщика Hrust 1:
- dehrust_ix.asm — распаковщик помедленнее, использующий индексные регистры. Занимает 234 байта, использует AF, BC, DE, HL, BC', DE', HL' и IX, в среднем распаковывает один байт за 132 такта процессора.
- dehrust_stk.asm — распаковщик пошустрее, релоцируемый (!), но, к сожалению, читающий данные стеком. Занимает 209 байт, использует AF, BC, DE, HL, BC', DE', IX, и, внимание, HL', распаковывает байт за 120 тактов.
Hrust 2 — упаковщик Дмитрия Пьянкова, который позиционировался для упаковки текстов. Возможно, старые спектрумовские упаковщики давали какие-то различия при упаковке в эти два формата. Как покажут тесты ниже, при использовании оптимальных пакеров, преимущество Hrust 2 перед Hrust 1 на текстах очень невелико, а на смешанных данных Hrust 2 проигрывает Hrust 1 около 0.6%. Алгоритм упаковки — навороченный LZSS. Оптимальный пакер для Hrust 2 не так давно опубликовал Евгений Ларченко. Он называется oh2c.exe, и вызывают его следующим образом:
oh2c.exe inputfile [outputfile.hrust2]У формата Hrust 2 есть официальный распаковщик:
- DEHRUST_2x.asm занимает 212 байт, использует AF, BC, DE, HL, BC', DE' и, внимание, HL', и распаковывает байт данных за 127 тактов.
LZ4 — один из модных упаковщиков данных новой волны, разработанный Yann Collet, см. страницу проекта. Это байтовый LZSS упаковщик, угу, примерно как старый пакер Titusa. Байтовые упаковщики встречались иногда в 1990е, но быстро проиграли смешанным битовым-байтовым пакерам, т.к. не могли конкурировать по коэффициенту сжатия. Почему к ним вернулись, тем более на современных компьютерах? Дело в том, что разница в скорости между вычислениями на современных процессорах и доступом к памяти настолько велика, что распаковка сжатых данных оказывается быстрее тупого копирования заранее приготовленных данных, т.е. упаковка под очень быстрый распаковщик — способ ускорения работы программ, ворочающих большими кусками данных. Вообще, библиотек похожего назначения сейчас очень много (Snappy, FastLZ, QuickLZ, LZTurbo, LZO, LibLZF). Я выбрал LZ4 из-за того, что, по меркам таких библиотек, он сравнительно неплохо пакует и ещё потому, что для него уже было написано несколько распаковщиков под Z80. Паковать в формат LZ4 лучше всего используя оптимальный компрессор smallz4.exe, с вот таким форматом вызова:
smallz4.exe -9 inputfile [outputfile]Я тестировал следующие распаковщики:
- unlz4_drapich.asm — самый навороченный распаковщик, написанный Piotr Drapich (я скачивал его здесь). Он тщательно проверяет сигнальные байты и заголовки ZX4 и, видимо, должен справиться с файлами в устаревших версиях формата. Расплата за такую добросовестность — сравнительно большой размер распаковщика — 251 байт. Используются регистры AF, BC, DE, HL, AF' и IX. В оправдание своей репутации на больших машинах, очень высокая скорость распаковки — 33.8 такта на распакованный байт.
- unlz4_stephenw32768.asm — сильно упрощённый распаковщик авторства stephenw32768 с WoS, который умеет работать только с очищенными от заголовков упакованными данными. Автор распаковщика написал специальную утилиту для удаления заголовков, так что данные приходится паковать в два шага:
Полученный бинарник уже можно распаковывать. Скорость распаковки слегка ниже — 34.4 такта на байт, но зато распаковщик занимает всего 72 байта.smallz4.exe -9 inputfile outputfile.lz4 lz4-extract.exe < outputfile.lz4 > outputfile.lz4raw - В конце обзора приложен мой новый распаковщик для LZ4 — unlz4_spke.asm, который занимает 104 байта и распаковывает данные немного быстрее чем unlz4_drapich.asm — по 33 такта на распакованный байт, т.е. почти уже как 1.5*LDIR. Мой распаковщик проверяет заголовки только очень поверхностно, для сокращения размера и ускорения работы. При желании, опция DATA_HAS_HEADERS может быть закомментирована, что переведёт распаковщик в режим работы с голыми данными без заголовков, такими, как готовит утилита lz4-extract.exe. Это слегка уменьшит размер данных и распаковщика, а также незначительно ускорит распаковку. Дополнительная опция ALLOW_USING_IX слегка добавит скорости, если вы можете позволить себе потерять значение в IX.
MegaLZ — модный упаковщик, разработанный fyrex. Технически, он представляет собой LZSS пакер средней степени сложности. Насколько я понимаю, благодаря трудам lvd, MegaLZ оказался одним из первых (первым?!) пакером для спектрума с оптимальным парсером (см. зеркало старой домашней страницы). Это позволяло MegaLZ конкурировать по сжатию с лучшими LZ пакерами на платформе (типа Hrust 1, оптимальный пакер которого написали только совсем недавно). Сейчас есть два оптимальных пакера для MegaLZ: megalz.exe и mhmt.exe. Ссылку на дистрибутив mhmt я дать не могу, т.к. ни одной страницы с релизом найти не смог; старая страница Google Code пустая. Упаковщик вызывается так:
megalz.exe inputfile [outputfile.megalz]mhmt.exe -mlz inputfile [outputfile.megalz]Я знаю только один распаковщик для MegaLZ.
- DEC40.asm — 110 байт релоцируемого кода. Скорость распаковки — около 131 такта на распакованный байт. Используются регистры AF, BC, DE, HL и AF'.
Pletter 0.5 — если верить нескольким замечаниям на форумах, Pletter является достаточно популярным упаковщиком на MSX.
Тем не менее, информации о Pletter в сети достаточно мало. Разработан Pletter командой XL2S Entertainment в 2007-2008 (см. дом страницу проекта). По сути, это, примерно так же как и ZX7, развитие компрессора BitBuster, т.е. ещё один простой битово-байтовый LZSS пакер. Тем не менее, в отличие от BitBuster/ZX7, Pletter пытается быть гибче в своём формате. Если очень коротко, формат хранения данных BitBuster довольно туповат. Тем не менее, он явно основан на данных каких-то статистических тестов, так что если начать слегка варьировать формат упаковки, размер упакованных файлов обычно растёт в среднем. Т.е. формат BitBuster — в каком-то смысле локальный оптимум. Что делает Pletter — он слегка обобщает формат ссылок (всего 6-7 вариаций). Старый Pletter 0.4 просто состоял из универсального упаковщика и семи распаковщиков, что довольно неудобно. Новый Pletter 0.5 (текущая версия 0.5c1) сам пытается паковать с каждой вариацией формата и пишет упакованный файл в самом удачном формате. Первые 3 бита файла кодируют использованную вариацию формата, чтобы настроить по ней распаковщик. Даже такая небольшая адаптация формата существенно повышает среднее сжатие, при этом почти не влияя на скорость распаковки. Упаковка в Pletter 0.5 делается так:
pletter5.exe inputfile [outputfile.plet5]В комплекте с Pletter 0.5 приложен только один распаковщик:
- unpletter5.asm — 170 байт нерелоцируемого кода, использующего, внимание, ВСЕ регистры (кроме IR :) ). Скорость распаковки — 75 тактов на распакованный байт.
Pucrunch — один из очень навороченных старых пакеров, с корнями на C64 (вот исходные файлы проекта). Я не стал детально разбираться в этом упаковщике; я знаю, что это некая достаточно сложная вариация LZSS, с репутацией медленной распаковки. Из пространных пояснений автора понятно, что он точно сделал в своём упаковщике lazy evaluation. Это означает, что пакер Pucrunch — оптимизирующий; является ли упаковщик ещё и оптимальным — неясно. В любом случае, упаковать файл без встроенного распаковщика и дополнительных заголовков можно используя слегка хакнутую версию Pucrunch, сделанную автором sjasmplus Aprisobal. Командная строка выглядит так:
apri_pucrunch.exe -d -c0 inputfile [outputfile.pu_apri]Сборка Aprisobal содержит один распаковщик:
- apri-uncrunch-z80fast.asm — занимает 255 байт и распаковывает один байт данных за 301 такт (в среднем).
ZX7 — очень раскрученный на WoS упаковщик, написанный Einar Saukas. Официальный релиз можно скачать с WoS. Упаковка данных делается так:
zx7.exe inputfile [outputfile.zx7]- ZX7 не хранит распакованную длину данных (экономия двух байт на сжатый блок);
- Bitbuster хранил длину совпадений после смещения (это экономит один бит на сжатый блок)
- В Bitbuster использовались инвертированные Elias Gamma коды (0<->1, не думаю, чтобы это что-то экономило, хотя, возможно, это чуть упростило упаковщик).
Одно существенное достоинство ZX7 — довольно серьёзно оптимизированные распаковщики (написать их помогали те же ребята, которые занимались оптимизацией распаковщиков ApLib и Exomizer).
- dzx7_standard.asm — «стандартный» распаковщик оптимизирован по длине и занимает всего 69 байт. Тем не менее, простота формата позволяет ему оставаться достаточно быстрым — около 107 тактов на распакованный байт. Используемые регистры: AF, BC, DE и HL;
- dzx7_turbo.asm — существенно более быстрый распаковщик длиной 88 байт, который распаковывает байт меньше чем за 81 такт;
- dzx7_mega.asm — оптимизированный на скорость распаковщик длиной 244 байта, 73 такта на распакованный байт;
- dzx7_lom_v1.asm — так как я активно использовал ZX7 в своих проектах, я написал свой собственный оптимизированный на скорость распаковщик. Используемые регистры: AF, BC, DE, HL и IX. Ускорения оказались возможны за счёт учёта вероятностей условных переходов; новый распаковщик занимает 214 байт и распаковывает байт в среднем за 69 тактов.
Результаты тестов
Перед началом теста я упаковал данные двумя ведущими упаковщиками. Rar 4 (a -r -m5) упаковал мой набор данных до 559575 байт; 7-zip (a -r -ms=off) упаковал эти же данные до 550330 байт. В обоих случаях склеивание файлов перед сжатием было отключено. Эти цифры можно считать нашим, скорее всего недостижимым, идеалом. Вот что показали результаты включённых в тест упаковщиков:
unpacked ApLib Exomizer Hrum Hrust1 Hrust2 LZ4 MegaLZ Pletter5 PuCrunch ZX7
Calgary 273526 98192 96248 111380 103148 102742 120843 109519 106650 99041 117658
Canterbury 81941 26609 26968 31767 28441 28791 34976 31338 30247 27792 32268
Graphics 289927 169879 164868 173026 169221 171249 195544 172089 171807 169767 172140
Music 151657 59819 59857 62977 60902 62678 77617 62568 63661 63977 66692
Misc 436944 252334 248220 262508 251890 255363 293542 261396 263432 256278 265121
TOTAL: 1233995 606833 596161 641658 613602 620823 722522 636910 635797 616855 653879
Как видите, только один упаковщик смог опуститься ниже волшебной цифры в 600000 байтов. Эти же данные в виде коэффициентов сжатия (в процентах) выглядят следующим образом:
ApLib Exomizer Hrum Hrust1 Hrust2 LZ4 MegaLZ Pletter5 PuCrunch ZX7
Calgary 35.90 35.19 40.72 37.71 37.56 44.18 40.04 38.99 36.21 43.02
Canterbury 32.47 32.91 38.77 34.71 35.14 42.68 38.24 36.91 33.92 39.38
Graphics 58.59 56.87 59.68 58.37 59.07 67.45 59.36 59.26 58.56 59.37
Music 39.44 39.47 41.53 40.16 41.33 51.18 41.26 41.98 42.19 43.98
Misc 57.75 56.81 60.08 57.65 58.44 67.18 59.82 60.29 58.65 60.68
TOTAL: 49.18 48.31 52.00 49.72 50.31 58.55 51.61 51.52 49.99 52.99
Как видите, лучше всего жмутся пакеты «Calgary», «Canterbury» и «Music». Упаковка графики оказалась сопоставимой с упаковкой просто смешанных или, иногда, даже запакованных данных.
Интуитивно понятно, что ланчей даром не бывает. Чем лучше мы жмём данные, тем больше нам придётся вычислять при распаковке, тем медленнее окажется наш распаковщик. Поэтому имеет смысл предположить, что существует некое теоретическое максимальное сжатие для каждой скорости распаковки, ну или максимальная скорость распаковки для каждого коэффициента сжатия, ограниченные только производительностью нашего компьютера. Кривую, которая описывает эту оптимальную зависимостью между степенью сжатия и скоростью распаковки, я буду называть гранью оптимальности по Парето. Мы не знаем где именно она проходит, но мы можем догадаться где она примерно находится глядя на производительность уже существующих упаковщиков.
Какой смысл гадать о теоретической грани оптимальности? Если очень коротко, она позволит нам понять, какие упаковщики наиболее эффективны в своей категории. Чем ближе упаковщик находится к грани оптимальности, тем более эффективно он использует вычислительные возможности компьютера для эффективной распаковки хорошо упакованных данных. То есть, мы не будем сейчас мерить одни только коэффициенты сжатия или скорости распаковки. Вместо этого, мы выясним, где примерно находится грань оптимальности и сможем оценить, какой компрессор наиболее быстро распакуют данные с нужным нам коэффициентом сжатия или, наоборот, какой компрессор наиболее плотно упакуют данные, если нам нужно достичь заданной наперёд скорости распаковки.
Исходя из этих соображений, я обработал данные выше, и объединил их с измерениями скорости распаковки, которые я привёл описывая распаковщики (хочу отметить, что скорость была измерена только на наборах данных «graphics» и «music»). Результаты этих измерений можно найти выше, там где я привёл подробное описание каждого пакера. Результатом этой работы стал следующий график:
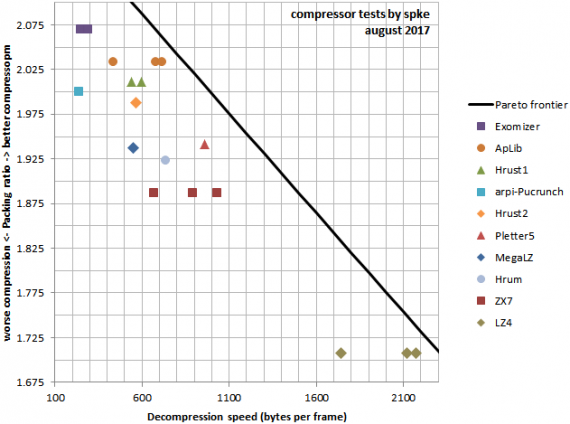
который позволяет сделать некоторые…
Общие наблюдения и выводы.
- Условно, я бы разделил все распаковщики на несколько групп, выбранных исходя из сложности алгоритмов и тесно связанной с этим скоростью распаковки.
- Самое большое сжатие на сегодняшний день обеспечивает упаковщик Exomizer (в среднем, он сожмёт ваши данные более чем в два раза). Расплатой за это служит низкая скорость распаковки — около 250 тактов на каждый распакованный байт. Судя по расстоянию до грани оптимальности Парето, у пакеров с сопоставимым коэффициентом сжатия должен ещё быть немалый запас по скорости распаковки. К сожалению, конкурентов у Exomizer сейчас нет.
- Во вторую группу я бы отнёс «сложные» LZ пакеры: Hrust 1 и 2, Pucrunch и ApLib. ApLib — очевидный лидер, как по сжатию, так и по скорости распаковки. Коэффициенты сжатия у остальных упаковщиков в этой группе сопоставимы; Hrust 1 жмёт слегка лучше, Hrust 2 жмёт слегка хуже. Тем не менее, ApLib обычно сожмёт ваши данные на 0.5% лучше чем Hrust 1 и распакует их на 20% быстрее, используя распаковщик меньшего размера (быстрый, т.е. стековый распаковщик Hrust 1 длиной 209 байт тратит примерно 120 тактов на распакованный байт; второй по скорости распаковщик ApLib занимает 199 байт и тратит около 105 тактов на байт). Когда мне понадобится сопоставимый коэффициент сжатия, я лично буду использовать ApLib с одним из быстрых распаковщиков.
- Pucrunch, очевидно, уже морально устарел. Hrust 2 явно проигрывает Hrust 1 и не имеет никаких очевидных достоинств, так что, видимо, тоже неконкурентоспособен. Упаковщик для Hrust 1 — оптимальный, в то время как все упаковщики для ApLib — оптимизирующие, поэтому разрыв в степени сжатия может ещё слегка подрасти. Отсюда следуют такие выводы: Hrust 1 может занять уникальную нишу только если кто-то напишет для него новый компактный распаковщик, ускоренный раза в полтора. Когда/если кто-то напишет оптимальный пакер для ApLib, Хруст 1, вероятно, придётся отправить на пенсию.
- В третьей группе оказалась смесь из LZ пакеров попроще, таких как MegaLZ, Hrum, Pletter и ZX7. Раньше, до написания этого обзора, мне казалось, что когда вам хочется чуть побольше сжатие, а скоростью можно пожертвовать — MegaLZ или Hrum будут неплохими кандидатами. Тем не менее, сейчас я вижу, что скорость распаковки MegaLZ и Hrum вполне сопоставима со скоростью распаковки Hrust 1 или ApLib, а коэффициент их сжатия намного меньше. Получается, и MegaLZ, и Hrum уже морально устарели — хотя если бы их распаковщики можно было ускорить в 1.5-2 раза, они бы снова нашли себе применение. Почти во всех моих демо я жертвовал сжатием и использовал ZX7, т.к. в трекмо обычно бывает важнее скорость распаковки. Тем не менее, посмотрев на результаты Pletter 5, я не могу не сделать вывод что ZX7 тоже морально устарел, поэтому лично я сейчас переключаюсь на Pletter 5.
- В четвёртой группе у меня снова только один распаковщик, LZ4. Это единственный байтовый пакер в обзоре. С учётом совершенно нереальной скорости распаковки — в среднем, около 34 тактов на распакованный байт, т.е. примерно 1.5*LDIR, видимо и нам на спектруме тоже есть смысл начать задумываться о компрессии, как способе повышения пропускной способности доступного нам железа. Только задумайтесь, LZ4 может распаковывать больше 2Кб данных за фрейм!
- Группа кодеров, которые оптимизировали стандартные распаковщики Exomizer, также сделали перепаковщик упакованных файлов Exomizer, позволяющий дополнительно ускорить распаковку. Я не вникал в их работу, по-моему они наворотили там что-то слишком сложное, но это ещё раз подсказывает, что распаковщик Exomizer всё ещё может быть ускорен.
- Разрыв по сжатию между Exomizer и следующими за ним ApPack и Hrust 1 достаточно невелик. Думаю, для приложений, требующих высокого сжатия, было бы интересно увидеть новые пакеры в этом диапазоне, но в этой категории упаковщиков трудно ждать существенных революций, так как технологии более эффективного сжатия (например, арифметическое кодирование или PPM), как правило, потребуют существенного замедления и, зачастую, немалых объёмов памяти для разжатия. См., например, ветку развития RIP, mRIP и т.п.
- Упаковка на PC позволила реализовать оптимальную упаковку уже во многих упаковщиках. Скорость оптимальных упаковщиков часто невысока, но большая производительность PC и небольшой размер актуальных для спектрума файлов делает оптимальную упаковку, там где она возможна, вполне практичной.
- Успех Pletter 5, особенно в сравнении с MegaLZ, показывает, что вместо переусложнения компрессоров специализированными кодами для каких-то специальных ситуаций, можно пытаться делать очень простые LZ компрессоры с оптимальной упаковкой и динамической адаптацией распаковщика к конкретным данным. Сказать по совести, Pletter 5 очень примитивен; думаю, что в этой области есть большой потенциал роста коэффициента сжатия без существенной потери скорости распаковки — было бы неплохо отодвинуть грань оптимальности немного дальше.
- Разрыв по коэффициентам сжатия между байтовыми и смешанными битово-байтовыми упаковщиками сейчас очень велик, но опыт быстрых упаковщиков на PC подсказывает, что этот разрыв можно сократить. Алгоритмы типа LZF или LZO на PC легко бьют LZ4 по сжатию и могут послужить основой для байтовых пакеров будущего, особенно если хорошо поработать над адаптацией их форматов под наши ограничения и под особенности Z80.
- Сравнительная простота ZX7 позволила ему оказаться самым быстрым смешанным битно-байтовым пакером в тесте. Тем не менее, расстояние до грани оптимальности по Парето у ZX7 настолько велико, что его неоптимальность очевидна. Ниша смешанных битово-байтовых пакеров, заточенных под не под сжатие, а под быструю распаковку на Z80, пока что, по сути, свободна.
- Простота формата ZX7 позволяет ему похвастаться самым коротким распаковщиком в этом обзоре, что актуально для изготовления мини-интр (256б, 512б или 1Кб). Почему у ZX7 получается в этом случае бороться с намного более эффективными упаковщиками? Разница в коэффициентах сжатия между лучшим пакером в обзоре и ZX7 — всего 52.99%-48.31%=4.68%. 5% от 1Кб — это 51 байт. С учётом того, что компактный распаковщик ZX7 занимает всего 69 байт, получается, что распаковщик Exomizer должен быть короче 69+51=120 байт, чтобы распаковщик+данные Exomizer заняли, в среднем, меньше места чем выходит у ZX7.
Совсем короткая памятка для тех кто не любит многобукв
- «Мне нужно самое большое сжатие, мне не важно, как долго оно потом будет распаковываться» => Exomizer;
- «Мне важно сжать получше, но я не могу тратить больше чем 110 тактов на байт распакованных данных» => ApLib;
- «Мне важно иметь возможность быстро распаковать мои данные (не больше 75 тактов на распакованный байт), не слишком теряя коэффициент сжатия» => Pletter 5;
- «Меня интересует только высокая скорость распаковки, сжатие — просто приятный бонус» => LZ4;
- «Я очень люблю релоцируемые распаковщики» => Hrust 1 со стековым распаковщиком, Hrum если нужен распаковщик поменьше, MegaLZ если важно отказаться от привязки к стеку;
- «Я делаю миниинтры (от 256б до 1кб), и для меня очень важен малый размер распаковщика» => ZX7 (69 байт — стандартный распаковщик, 88 байт — версия «turbo»). См. также ZX7mini, с распаковщиком от 39 байт, который, впрочем, пакует данные даже ещё хуже чем LZ4.
Я понимаю, что невозможно обозреть необозримое. Разумеется, я не мог посмотреть на все упаковщики на планете. Некоторые просмотренные упаковщики показались мне неинтересными, так что я не стал включать их в обзор. Много информации просто пропало. Поэтому, я буду очень рад поболтать вообще о пакерах, которыми вы пользуетесь и м.б. даже буду что-то знать о некоторых из них. Будет здорово, если вы сможете поделиться тут в комментариях своими секретами сжатия, или даже неопубликованными ранее know how. Удачи в компрессии ваших данных!
Приложение
Поскольку искать всю эту информацию по интернету было довольно мучительно, я собрал пакет информации по упаковке данных для z80. Туда включены собранные в сети релизы и другие вспомогательные данные почти о каждом из включённых пакеров, из которых я извлёк всё, что требуется для работы с каждым конкретным упаковщком. Всё это добро лежит здесь: compression2017.7zКроме этого, я решил сделать релиз двух своих секретных распаковщиков. Первый из них — это новый распаковщик для ZX7, который использовался ранее в нескольких релизах с моим участием, включая демо Break/Space. Моя версия распаковщика быстрее чем стандартный распаковщик dzx7_mega.asm примерно на 4% и занимает на 30 байт меньше памяти. В среднем, вы можете рассчитывать на то, что мой распаковщик потребует около 69 тактов процессора на каждый распакованный байт: dzx7_lom_v1.asm
Второй распаковщик я написал для формата ZX4, собрав все лучшие идеи из уже существующих распаковщиков. Новый распаковщик занимает 103 байта и работает на 2% быстрее распаковщика от Piotr Drapich; на каждый распакованный байт мой распаковщик тратит около 34 тактов Z80: unlz4_spke.asm
Приложенный распаковщик Hrum, тоже, отчасти, новый. Внутри это стандартный распаковщик Hrum, я просто слегка переписал его интерфейс (и испортил форматирование!!!). Он занимает 104 байта и тратит на распаковку байта 97 тактов: unhrum_std.asm
51 комментарий
А почему «внимание IY»? =)
В принципе, мне бы нужно было точно так же сказать про HL', потому что если в HL' неправильная величина, вернуться из распаковщика в Бейсик будет затруднительно.
Немного скажу за zx7. Cуществует версия пакера zx7b * Modified in 2013 by Antonio Villena, какие то файлы жмет лучше, какие то хуже, но думаю автора депакера хуже бы делать не стал? Он сам ей всегда и пользуеЦЦа.
Главное достоинство распаковки задом наперёд — можно иметь кодовый блок заканчивающийся на самом верху памяти и распковывать внахлёст просто загрузив упакованный блок так, чтобы его начало оказалось немного ниже начала распакованного блока. В 1990е я написал несколько пакеров на спектруме; они были очень примитивные, но паковали они все задом наперёд как раз из-за того, что я переделывал мультифейсные кассетные релизы и мне часто бывало нужно распаковать в упор до конца памяти.
CharPres. Настолько херово жмет, что им по два раза жали:)
Offtopic.
Нарыл у себя в тестах немного данных по разным архаичным и не очень упаковщикам.
16384 байта TR-DOS Ver 5.03 (md5 0da70a5d2a0e733398e005b96b7e4ba6)
Размеры со всеми заголовками и депакерами (если без него нельзя). Для архивов — размеры блока файла со всеми заголовками.
Так получилось, что CodeCruncher3 и Data SQueezer тестировались на других данных, поэтому в сравнении не участвуют.
По факту, без депакера там только HRiP/RAR/ZIP/ZXZIP
У остальных форматов (кроме MegaLZ) в коде депакера содержится часть информации о сжатых данных (как минимум, размер). Так что просто вычесть из длины упакованного блока размер распаковщика нельзя.
он хоть и специфичный, но жмет то без потерь, и все равно что…
Эталон этот в три раза сжимает, до 5215. Распаковывает конечно медленно, но на картинках — красиво:)
ну и картинки уж точно вряд ли кто сильнее жмет.
dizzy4k/c2h5oh unpacked
интересно, насколько все изменилось сейчас, c2h5oh может и поменьше получиться, там сразу после релиза я табличку построения синуса менял на инкрементную, — должно сказаться на паковке…
возможно, возможен «optimal hrum packer», как для hrust'а? ;)
Хотя, нужно будет расследовать, как именно там выбираются моменты для вставки кодов расширения ссылок в Hrust 1, потому что я что-то не совсем понимаю как это можно сделать оптимально, особенно с учётом того, что укорачивать коды вроде тоже декомпрессор позволяет.
Действительно, благодаря тому, что в декомпрессоре используется циклический сдвиг (RRC D), регистр D можно сбросить до начального состояния. oh1c это учитывает. Это улучшает сжатие в среднем на 0.02% ;)
ApPack, Hrum, MegaLZ на этом масштабе почти неразличимы, чего и следовало ожидать по итогам больших тестов.
sp_save: ld sp,0
->
sp_save: ld sp,__sp
ifdef FORPACK
__sp equ #3131
__hl equ #2121
__de equ #1111
__bc equ #0101
else
__sp equ 0
__hl equ 0
__de equ 0
__bc equ 0
endif
при паковке hrum'ом, — лучше было оставлять ld sp,0, иначе наоборот + 3 байта на всю интру еще и добавит :)
c exomizer'ом же — 3 байта уберет.
;)
Ещё возил программу по памяти, чтобы константы брать из случайных регистров. Ещё, в самом конце уже, модифицировал распаковщики, чтобы сберечь несколько бит на настройках уже самого распаковщика (скажем, zx7mini копирует первый байт вслепую, а потом уже следит по битовому потоку. У меня выходило, что всё равно первые 6-8 байт не паковались, поэтому я просто копировал их автоматом, меняя настойки самого распаковщика).
«Splash 1K» и «Chaos Construction 1K» используют ZX7 со стандартным распаковщиком.
А вообще, компрессия — реально другой способ делать size-intro. Требует другие навыки, во многом ортогональные нормальному size-coding. Поэтому, с моей точки зрения, это скорее способ поддержать основы, путём увеличения видового разнообразия.
В следующем материале попрошу разобрать проблему, каждую осень волнующую неокрепшие умы — «Bruteforce sizecoding на своременных вычислительных мощностях: вкалывают роботы, а не человек!»